
Insurance Fraud Detection
How I built a predictive model to flag fraudulent claims using XGBoost — and what I learned about the importance of business context in feature selection.
Why this project?
Insurance fraud costs the industry billions annually, and companies are constantly seeking ways to detect and prevent it. I wanted to tackle a real-world problem with significant financial implications and was specifically looking to work on a predictive model with a binary outcome in this case fraud or not fraud.
The subject matter was also a fantastic example of an imbalanced dataset. As I'll get into later the fact that most of the data is skewed towards legitimate claims made this project more challenging, and as a result more satisfying to complete.
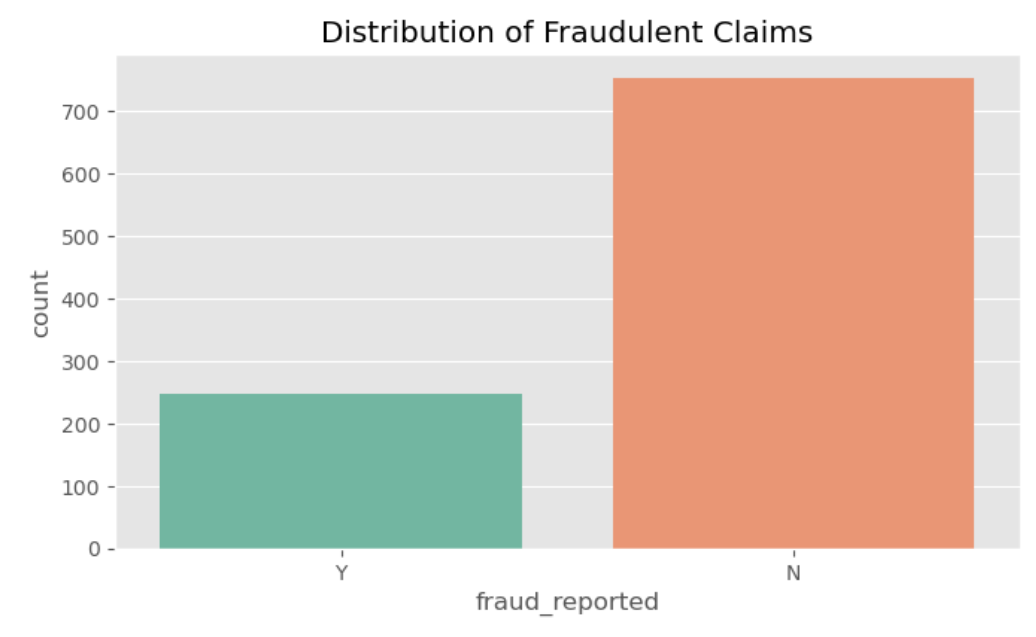
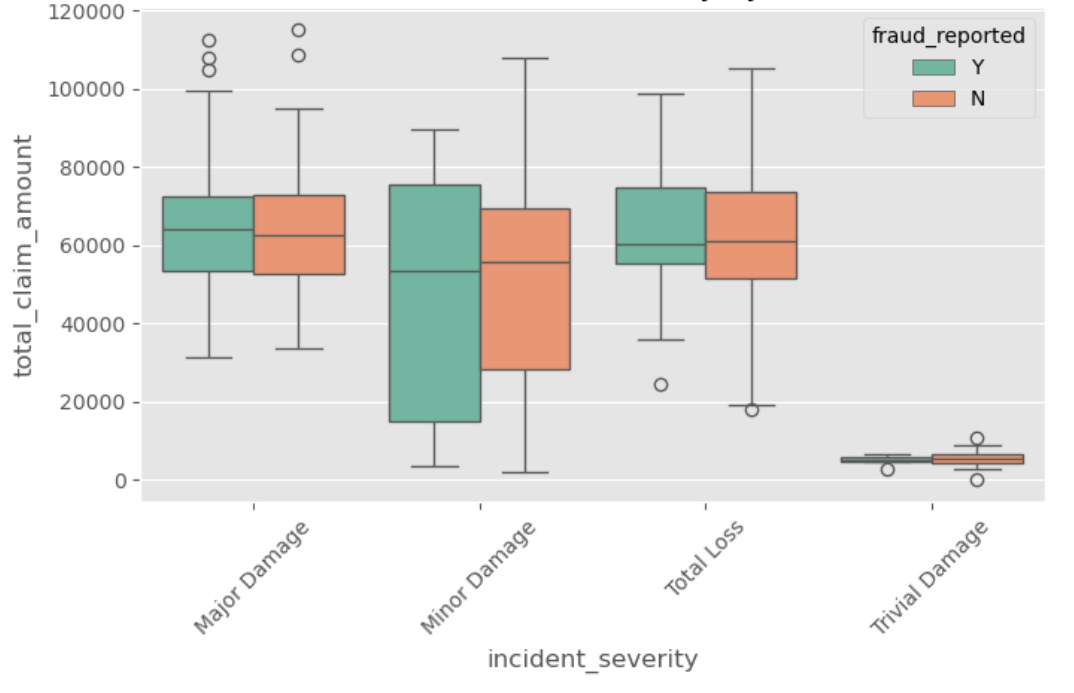
Exploratory Data Analysis
Before jumping straight into model building, I needed to understand the shape of the data. This step confirmed what some of the challenges of working with this dataset would be:
- Severe Class Imbalance: Given the way legitimate claims outweight fradulent ones in this data set, I recognized I would have to be careful about what metrics I focused on for this project. Simply guessing legitimate every time on this data set would result in pretty high accuracy at face value.
- Outliers and Non-linearities: Variables like
total_claim_amounthad massive outliers, and the relationship between a driver's age and fraud likelihood wasn't a simple straight line.
These discoveries lead me to decide on the Random Forest model for this project at first.
How it works & Model Decisions
The project is built entirely in Python using a Jupyter Notebook, keeping the focus strictly on data exploration and model building. The dataset comes from Kaggle, I've linked it below, and in the notebook
At this point you might have noticed the discrepancy between the model in the subtitle and in the last paragraph. Random Forest was ultimatly not a fit for my purposes mainly because it wasn't great at handling the first problem of severe class imbalance. Tree-based models are great for tackling some of the problems with this data set, such as the inherently noisy data, extreme outliers and non-linear relationships between features and outcomes.I also has believed I could use the class weight parameter to alleviate the imbalance of fradulent claims. Unfortunately I realized the model was defaulting heavily towards the more common legitimate class even with the balanced weighting.
For the replacement model, I used a Gradient Boosting model provided through the XGBoost library. This model build's tree sequentially and has iterations correcting the errors of their predecessors. This is useful here because the minority case (fraudulent claims) tend to produce erros more often at first which gets them a disproportionate amount of attention in later trees. This instantly provided results and before even looking at specific numbers it was apparent based on the correlation graph that the majority of fraud cases were being identified.
Weighing Feature Impact
An extra detail I worked on was a bar graph measuring howw much weight certain features had on the model's predictions. The Saab 9-5 came out on top as the strongest feature that the model weighed towards fraud followed by the insurance policy being on chess. Conversely incidents where the claimant lost everything seems to be a signal legitimiacy.
Conclusions
Overall I was pretty happy with how this project turned out. The final model had a ROC AUC score of 0.84 and a recall of 82% on the fraud cases which I thought was pretty good given the imbalance of the dataset and the fact that I didn't do any feature engineering. More important than the specific numbers though, I learned alot about the value of doing exploratory data analysis before diving into working with models, and how important it is to maintain my knowledge of what models and libraries are out there. If I had been more familiar with Gradient Boosting from the start I may not have wasted time trying a random forest model that let 95% of fraud cases slip by. This project mainly serves as a proof of concept and a real production version could likely further improve the recall with strategies such as feature engineering new features from the existing ones
Takeaways
- 01 Gradient Boosting: I'll keep this mind when I have a problem that might be solved by having having trees directtly iterate on their predecessors, like a class imbalance
- 02 Next Steps: Knowing why a claim was flagged is as important as the flag itself. In a business environment, it would be helpful to next work on if the most important weighed features are actually statistically significant and if so why are they so conducive to fraud.
- 03 Real World Application: Building an accurate model is only step one; integrating the predicted probabilities into a triage workflow for investigators is the real value.